ResNet strikes back: An improved training procedure in timm
블로그 첫 글로 무슨 글을 쓸지 고민 하다가 논문 리뷰를 하기로 하고, 또 무슨 논문을 리뷰할까 찾아보다가 페이스북에서 ResNet strikes back: An improved training procedure in timm 이라는 논문이 나왔다는 게시글을 보고 논문을 살펴보았습니다.
이 논문은 pytorch-image-models github (a.k.a timm)의 원작자인 Ross Wightman의 논문입니다. Ross-Wightman-github 에 들어가보니 소개글에 아래와 같이 적혀있었습니다. 개인적으로 깊이 감명 받았습니다. 🤩
Always learning, constantly curious. Building ML/AI systems, watching loss curves.
아무튼, 이 논문은 모델을 학습하는데 있어서 기본적이면서도 유용한 테크닉들이 잘 소개되어 있으며, 제안하는 학습방법을 적용해서 top-1 acc를 75.3%에서 80.4% 으로 끌어올렸다는 점에서 인상적이라 블로그 첫 게시물을 이 논문으로 정했습니다. 백본을 학습 시키려는 분들에게 유용할 듯 합니다.
Introduction
이미지 분류 분야 등에서 모델의 성능은 다음과 같은 수식으로 정의할 수 있습니다.
여기서 $ A $는 아키텍처 설계(architecture design), $ \tau $는 하이퍼 파라미터(hyperparameters)같은 학습 설정(tranining setting), $ N $은 측정 노이즈(measurement noise)를 뜻합니다. 여기서 일반적으로 하이퍼 파라미터 집합 또는 방법 선택에서 최대값을 선택할 때 발생하는 과적합(overfitting)도 포함됩니다. 또한 다른 시드(seeds)로 표준 편차(standard deviation)을 측정하거나, 별도의 평가 데이터 세트(evaluation dataset)을 사용하거나, 전이 작업(transfer tasks)에 대한 모델을 평가하는 것과 같이 노이즈 $ N $을 완화시키기 위한 몇 가지 사례들이 존재합니다.
$(A, \tau)$에 대해 최적화 할 때 주어진 아키텍처 $A_{1}$에 대한 최적의 $\tau_{1}$이 다른 아키텍처 $A_{2}$에 대해 최적으로 학습이 진행된다는 보장은 없습니다. 따라서 동일한 학습 과정에서 모델을 비교할 때 다른 모델 보다 한 모델을 암묵적으로 선호하게 되는 경향이 있을 수 있습니다. 학습 절차와 아키텍처의 개선 결과를 구분하는 좋은 방법은 기준선(baseline)이 새로운 “구성요소(ingredients)”를 포함하도록 하고, 하이퍼 파라미터를 조정하는데 상당한 노력을 기울이는 것이 중요합니다. 또한 다음과 같이 리소스와 시간 제약 없이 각 아키텍처에 대해 가능한 최상의 학습 절차를 최적으로 채택해야하지만 현실적으로는 불가능합니다.
ResNet-50 모델의 ImageNet-1k-val 데이터세트에 대해 보고된 성능은 75.2% 에서 79.5% 사이입니다. baseline을 발전시키기 위해 충분한 노력이 있었는지는 알 수 없습니다. 따라서 본 논문에서는 학습 레시피만을 고려하여 해상도 224x224의 ResNet-50 모델(the PyTorch ResNet50)의 성능을 최적화 할 수 있는 방법들을 소개합니다.
본 논문 내용을 요약하면 아래와 같습니다.
- 모델 학습 방법은 하이퍼 파라미터 조정과 세 가지 epoch(100, 300, 600)에 따라 구분
- Mixup 및 CutMix 방법 적용
- 모델의 정확도 안정성 측정
- ImageNet-val의 성능과 ImageNet-V2에서 얻은 성능을 비교하여 과적합 문제를 다룸
- 최근 인기있는 모델들을 학습하고 성능을 재평가함
- 모델과 학습 절차를 같이 최적화 해야할 필요성에 대해 논의함
Related work
Image Classification
이미지 분류는 컴퓨터 비전의 핵심 문제이며, 벤치마크에서 가장 많이 사용됩니다. 특히 ImageNet에서 학습된 이미지 분류를 위해 사전 훈련된 모델은 탐지(Detection), 분할(Segmentation)과 같은 다양한 downstream 작업에서 사용됩니다.
The timm library
이 라이브러리는 이미지 분류 및 학습 방법을 위한 수 많은 모델에 대한 구현을 제공합니다. 사전 훈련된 가중치가 많은 모델에 포함되어 있습니다. 또한 이 논문에서 설명된 학습 절차에서 활용되는 데이터 증강(data augmentation), 정규화(regularization), 최적화(optimizer), 학습률 스케쥴러(learning rate scheduler)의 구현이 포함되어있습니다.
ResNet
ResNet은 가장 널리 사용되는 이미지 분류 모델 중 하나입니다. 줄 곧 새로운 모델들을 소개하는 논문에서 baseline 으로 사용되어 왔습니다. 본 논문에서는 해상도를 변경하지 않고, 모델의 변경도 없이 최상의 학습 레시피만을 가지고 성능 향상을 이끌어내도록 합니다.
Training ingredients & recipes
이미지 분류를 위한 학습 구성요소와 레시피는 AlexNet이 시작된 이후로 크게 발전되어왔습니다. 시간이 흘러 여러 트렌드가 변경되기도 했으며 일반적으로 waterfall schedule 즉, 30 epoch 마다 학습률을 10으로 나눈다던지 더 길고 점진적인 스케쥴로 학습이 되어왔습니다. 또한 mixed precision을 사용하면서 batch size를 함께 늘리면 GPU를 더 잘 활용할 수 있습니다. 최근 더 좋은 data-augmentation 방법과 더 강력한 regularization, weight average를 사용하고, train 해상도를 test 해상도와 구별하기도 합니다. 또한 cross-entropy가 표준으로 남아있지만, 다른 loss 함수들도 실험되어 왔으며, 최적화는 SGD를 기본값으로 사용해왔습니다. RMSProp는 Inception, NASNet, AmoebaNet, MobileNet, EfficientNet과 같은 특정 CNN 모델에도 사용됩니다. transformer 와 MLP를 기반으로 하는 이미지 분류기를 학습하기 위해 AdamW, Lamb 등의 optimizer 등이 널리 사용되어 왔습니다.
Training Procedures
학습 절차는 다음과 같이 세 가지 절차를 따르게 되며, 해상도 224x224에서 ResNet-50 모델의 성능이 최상이 되도록 학습하게 됩니다. 다양한 옵티마이저, 정규화, 하이퍼 파라미터에 대해 grid search를 사용하여 수 많은 방법들을 탐색하게 됩니다.
✔️ Procedure A1
- epoch : 600
- training time : 4.6 day
- GPU : V100 (32GB) * 4
✔️ Procedure A2
- epoch : 300 (DeiT 등의 최신 모델들과 비교할 수 있는 epoch)
- batch size : 2048
✔️ Procedure A3
- epoch : 100
- batch size : 2048
- training time : 15h
- GPU : V100 (16GB) * 4
Loss: multi-label classification objective
Mixup 및 CutMix 증강 방법은 서로 다른 레이블을 가진 여러 이미지에서 이미지를 합성하는 방법입니다. CE(Cross-Entropy)를 사용하여 출력은 암시적으로 각 mixed concept이 존재할 확률로 처리됩니다. 학습에서는 이러한 개념이 모두 존재한다고 가정하고 분류를 다중 레이블 분류 문제(1 vs all)로 취급합니다. 이를 위해 일반적인 CE 대신 BCE(Binary Cross Entropy)를 채택합니다. 이 손실(Loss)는 Mixup 및 CutMix 데이터 증강 방법과 같습니다. 클래스가 다른 클래스와 독립적으로 Mixup 또는 Cutmix에 의해 선택된 경우 각 클래스에 대해 대상이 1로 정의 됩니다. (smoothing을 사용하는 경우 $1-\varepsilon$) 본 논문에서 찾아낸 학습 레시피에서 CE보다 BCE가 더 나은 성능을 보인다고 하네요!
Data-Augmentation
본 논문에서는 다음과 같은 데이터 증강 조합을 선택했습니다. (이 조합은 DeiT에서 사용)
- Random Resized Crop
- horizontal flip
- RandAugment / Mixup / CutMix
Regularization
weight decay 외에도 label smoothing, Repeated-Augmentation(RA), stochastic-Depth를 사용합니다. 더 긴 학습 일정을 위해 더 많은 정규화 방법들을 사용합니다. 예를 들면 A1에 대해서만 label smoothing을 채택합니다. RA와 stochastic depth는 모두 수렴에서 결과를 향상시키는 경향이 있지만, RA에 경의 초기 단계에서 학습 속도를 늦춥니다. 따라서 학습 일정이 짧을 경우 덜 효과적이거나 해로운 경향이 있어서 A1 및 A2에만 적용합니다. 다른 모델 또는 더 큰 ResNet의 경우 정규화를 추가하는 것이 유리하므로 이러한 모델에 대한 하이퍼 파라미터를 적용해야합니다. 예를 들어 ResNet-152의 경우 A2 레시피에 RandAugment, mixup, stochastic depth, 정규화를 추가하여 Imagenet-val에서 성능이 81.8%에서 82.4%로 증가합니다. 해상도 256x256에서 이 모델은 82.7%를 얻었으며 이는 다른 논문(모델 변경 전인 ResNet-200)에서 보고한 수치 보다 높습니다.
Optimization
AlexNet 이후로 convnet을 학습하는데 가장 많이 사용되는 옵티마이저는 SGD 입니다. 이에 반해 transformer 와 MLP는 AdamW 또는 LAMB 옵티마이저를 사용합니다. repeated augmentation 및 BCE 손실과 결합될 때 LAMB가 지속적으로 좋은 결과를 얻었음을 발견했습니다. 본 논문에서는 SGD와 BCE를 모두 사용할 때 수렴하기 어렵다는 사실을 발견했고, 기본 옵티마이저로 cosine schedule을 사용하는 LAMB를 채택합니다. 이 방법 말고, 다른 옵티마이저, 손실, 증강 및 정규화 조합을 사용하는 다른 학습 레시피는 부록 B에 기록되어 있습니다.
Experiments
Table 2. 다양한 논문에서 ResNet-50 학습에 사용되는 구성요소 및 하이퍼 파라미터 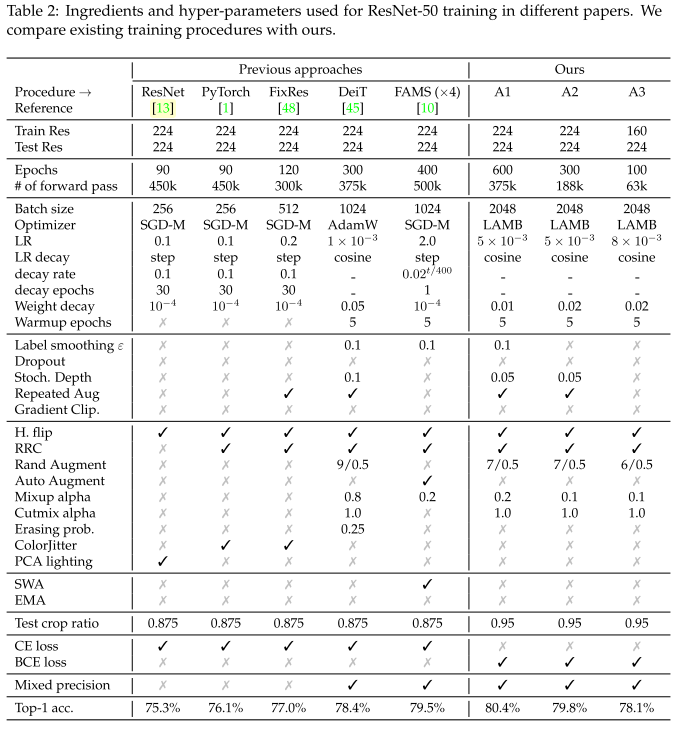
Comparison of training procedures for ResNet-50
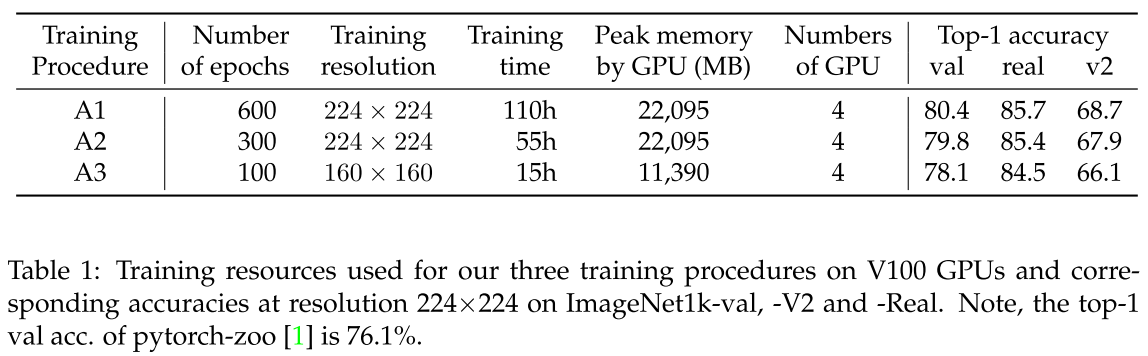
표 1은 학습 절차의 주요 특성을 요약해놓은 것 입니다. A1 방법은 224x224 해상도의 ResNet-50 모델에서 SOTA를 달성합니다. 다른 방법 A2, A3은 더 낮은 성능을 달성하지만 더 적은 리소스가 들며 여전히 높은 성능을 달성합니다.
Performance comparison with other architectures
표 3에서는 학습 절차에 따라 다른 모델들을 학습 할 때 얻은 성능들을 나타냅니다.
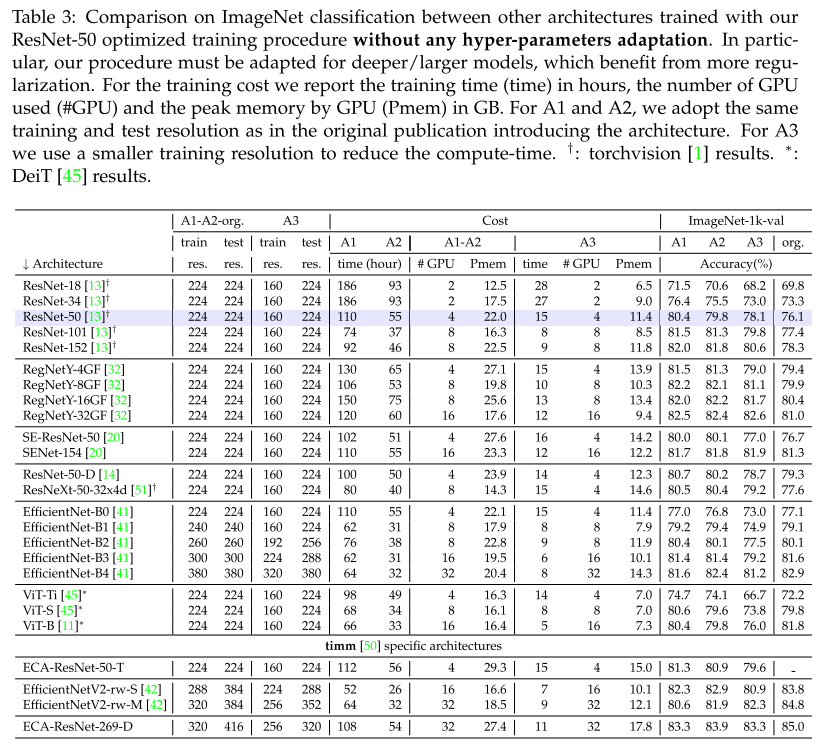
이를 통해 다른 모델에도 얼마나 잘 일반화 되는지 알 수 있습니다. ViT-B와 같은 일부 경우 A2 방법이 A1 보다 나은 것으로 관찰되기도 합니다. 이는 하이퍼 파라미터가 더 학습이 긴 일정에 적용되지 않음을 나타냅니다. (정규화가 더 필요함) 예를 들어 A2 방법은 ResNet-152를 학습할 때 81.8%의 정확도를 달성하지만 정규화를 약간 증가시켜 해상도 224x224에서 82.4%로 향상시켰습니다. 이는 해상도 256x256에서 평가할 때 82.7%을 달성합니다. 표3 에서는 다른 모델을 학습하는데 사용된 학습 레시피의 성능과 리소스를 비교합니다.
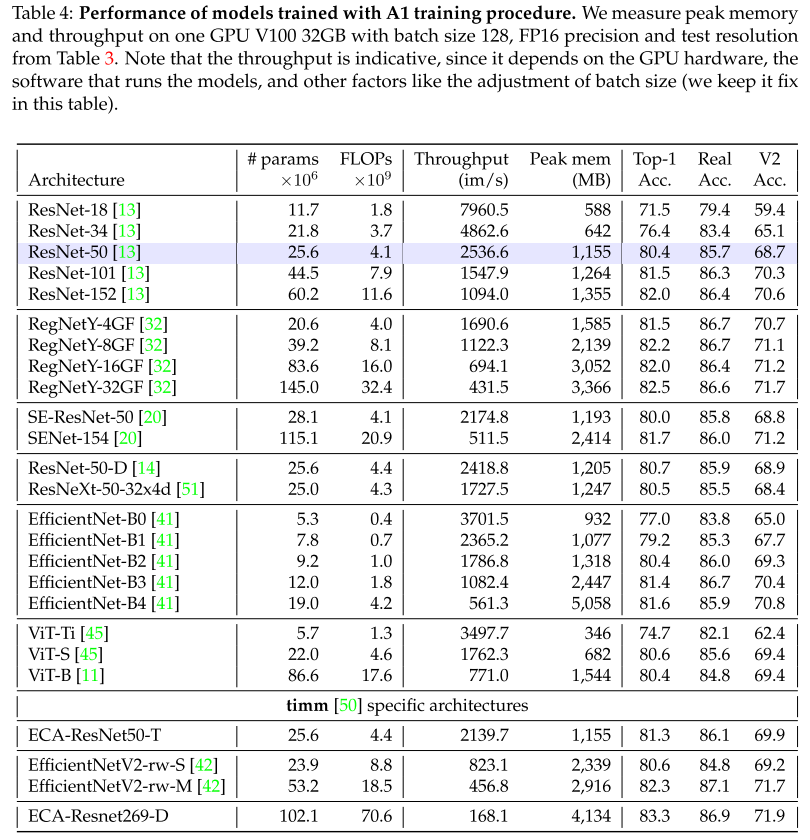
표4 로 이러한 결과를 보완합니다. 여기서 최고의 성능을 달성하는 A1 방법으로 학습된 다양한 모델에 대해 ImageNet-1k, ImageNet-V2 및 ImageNet-Real의 성능과 효율성을 설명합니다.
Significance of measurements: seed experiments
고정된 방법 및 하이퍼 파라미터의 경우 여러 단계에서 무작위 요소의 존재로 인해 성능에 고유한 가변성이 존재하게 됩니다. 가중치 초기화 뿐만 아니라 최적화 절차 자체의 경우도 마찬가지로 예를 들어, 이미지가 배치를 통해 네트워크에 공급되는 순서는 random generator에 따라 다릅니다. 이러한 변동성은 정확도 측정의 중요성에 대한 질문을 제기하게 됩니다. 이를 위해 random generator를 변경할 때 성능 분포를 측정합니다. 이전 연구에 의하면 시드를 변경하여 수행되며, 학습 절차의 평균 결과보다 성능이 훨씬 우수하거나 성능이 낮은 이상 값이 있다고 결론 지었습니다. 그림 1에서 100개의 고유한 시드를 고려할 때 A2 방법의 성능에 대해 여러 통계를 나타내게 됩니다.
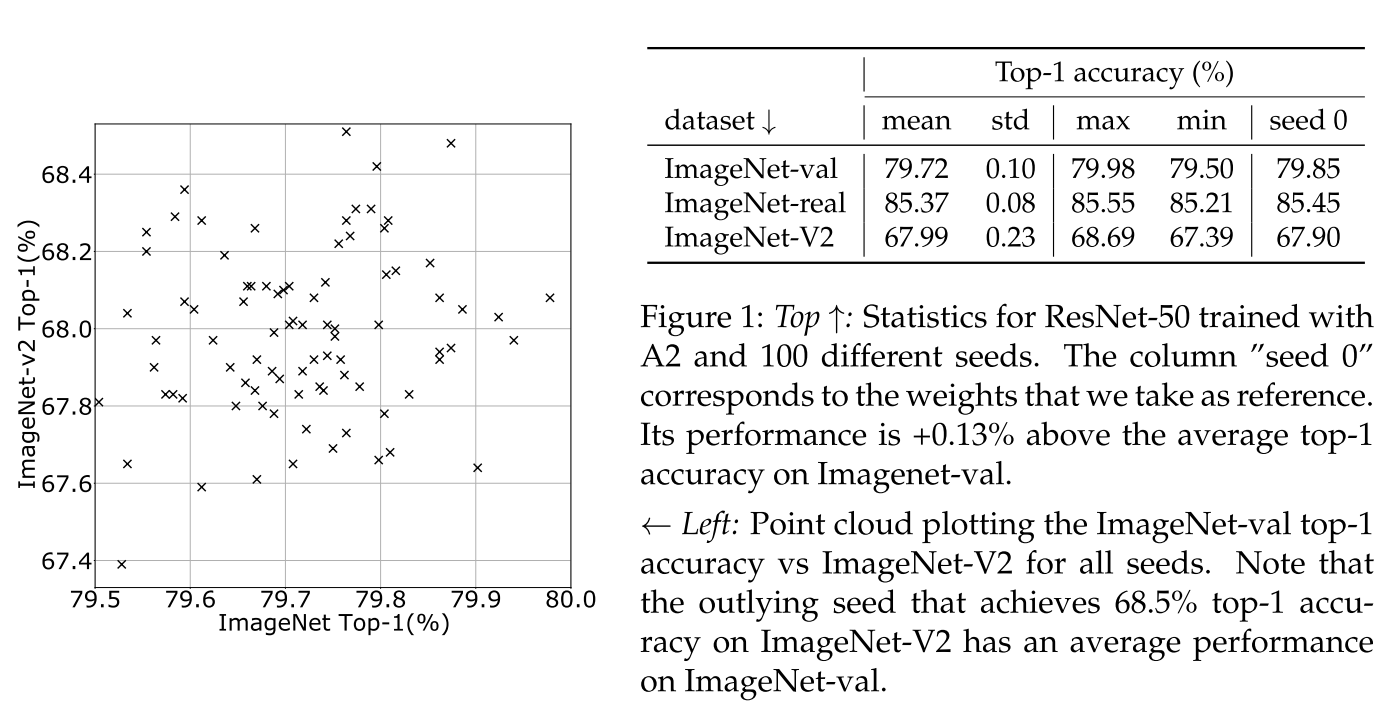
Peak performance and control of overfitting
validation의 정확도를 과대평가하는 것을 방지하기 위해 exploration 과정에서 final checkpoint만을 선택하였고, 하이퍼 파라미터 검색을 위해 상대적으로 coarse grid를 사용하여 추가적인 시드 효과가 일어나는 것을 방지합니다. 그림 1에서는 A2의 학습 절차에서 성능이 최대 80.0%에 가깝다는 것을 발견하였고, 그림 2에서는 정확도 분포를 히스토그램으로 제공합니다.
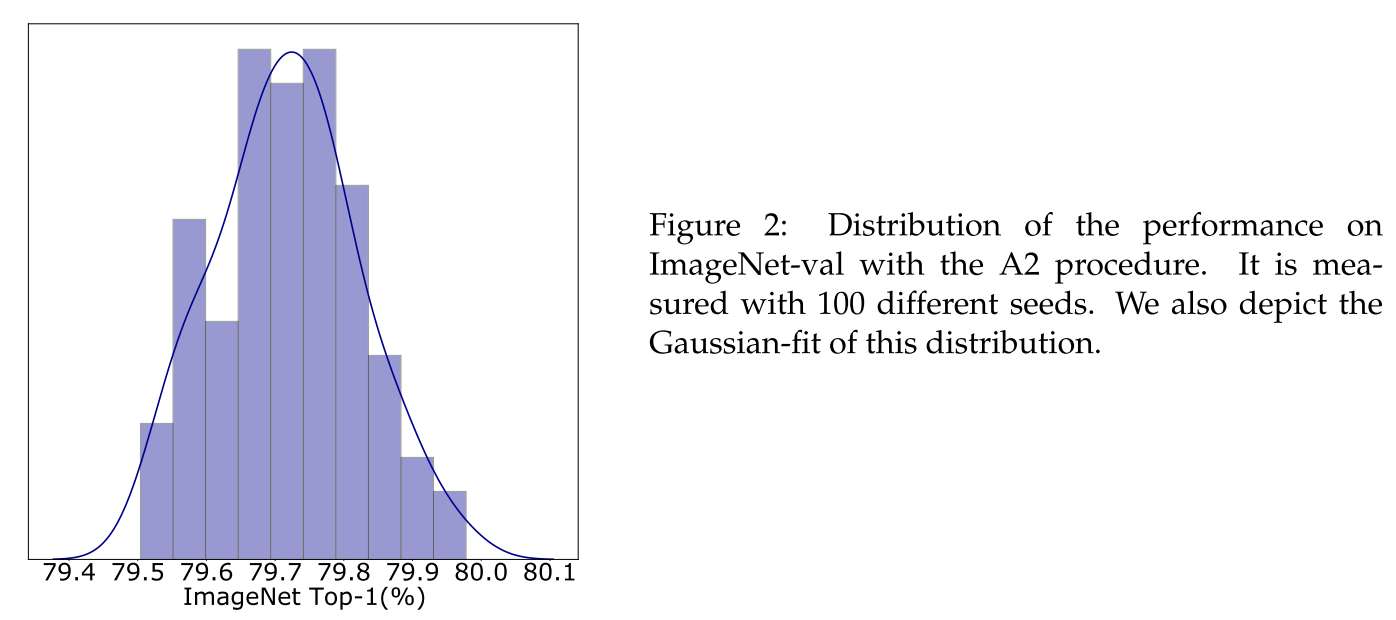
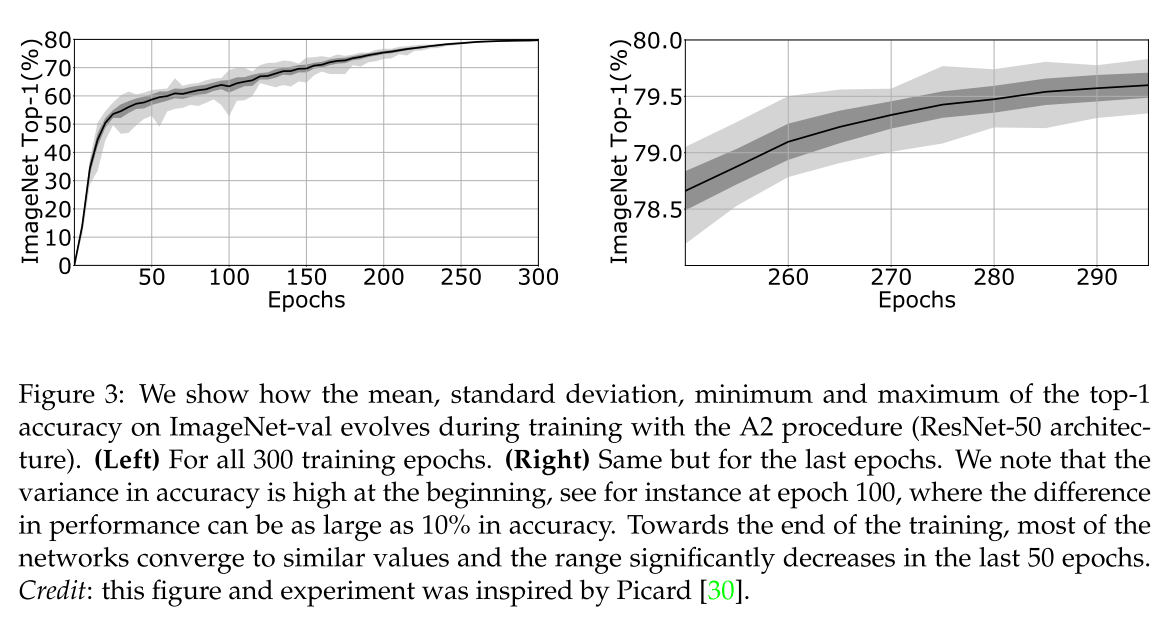
More on sensitivity analysis: variance along epochs.
그림 3은 epoch에 따라 성능 가변성이 어떻게 바뀌어가는지 보여줍니다.
Transfer Learning
표 5에서는 서로 다른 pre-training 절차를 사용하여 7개의 데이터 세트에 대한 transfer learning 학습 성능을 보여주고, 기본 PyTorch pre-training 과 비교합니다.
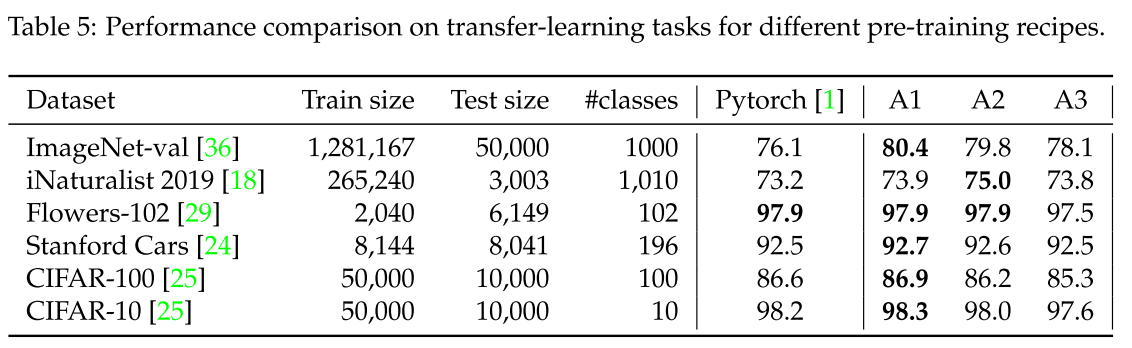
각 pre-training 에 대해 DeiT에 사용된 fine-turning 절차와 동일한 절차를 사용합니다. 각 데이터세트에 대해 fine-tuning 하이퍼 파라미터를 조정합니다. 이러한 fine-tuning은 CIFAR 또는 Stanford Cars와 같은 특정 데이터 세트의 성능 차이를 완화하는 경향이 있음을 발견하였습니다. 전반적으로 A1의 학습 방법은 downstream 작업에서 최상의 성능으로 이어지지만, PyTorch 기본 값과 A2의 성능은 유사한 경향이 있는 반면 ImageNet-val 및 v2에서는 훨씬 더 우수했습니다. A3은 160x160의 낮은 해상도와 관련 있는 downstream task에서 좋지 않은 결과를 보여줍니다.
Comparing architectures and training procedures: a show-case of contradictory conclusions
이 섹션에서는 동일한 학습 절차 하에 두 모델을 비교하는 것이 얼마나 어려운지, 또는 반대로 다른 절차를 단일 모델과 비교하는 것이 얼마나 어려운지를 설명하게 됩니다. ResNet-50 및 DeiT-S로 설명합니다. 후자의 방식은 기본적으로 ResNet-50과 거의 동일한 수의 파라미터를 갖도록 매개변수화 된 ViT 입니다. 각 모델에 대해 동일한 epoch 300 학습 일정과 동일한 batch size로 imagenet-val에서 성능을 극대화하기 위한 절차를 최적화 하기 위해 상당한 노력을 했습니다. 이러한 제약 하에 ResNet-50을 위해 설계한 최고의 학습 절차는 A2 입니다. 본 논문에서는 DeiT-S를 위한 학습 절차를 T2로 나타냅니다. 이 학습 절차는 DeiT-S에 대해 처음 제안된 것 보다 Imagenet-val에서 훨씬 나은 성능을 달성합니다. (80.4% versus 79.8%)

즉, A2 학습 방법을 통해 ResNet-50은 DeiT-S 보다 우수하며, T2 학습으로 DeiT-S는 ResNet-50 보다 낫습니다.
Ablations
이 섹터에서는 하이퍼 파라미터 또는 구성요소 선택에 대한 몇 가지 ablation 을 제공합니다. 일부 수정된 사항은 올바르게 작동하기 위해 여러 다른 파라미터들을 다시 조정해야 하므로 개별적으로 완화하기 힘듭니다. 특히 하이퍼 파리마터와 강하게 상호작용하는 옵티마이저가 특히 그렇습니다. 자세한 사항은 Appendix B를 참고하는 것이 좋을 듯 합니다.
Main ingredients and hyper-parameters.
표 6에서는 주요 구성요소들의 ablation을 제공합니다. 학습률은 학습에 중요한 영향을 미치며 $5.10^{-3}$ 값은 최상의 성능을 달성합니다. 그러나 이를 더 증가시키면 분산의 위험이 커질 수 있습니다. 일반적으로 weight decay 는 [0.02, 0.03] 범위에서 이루어집니다.
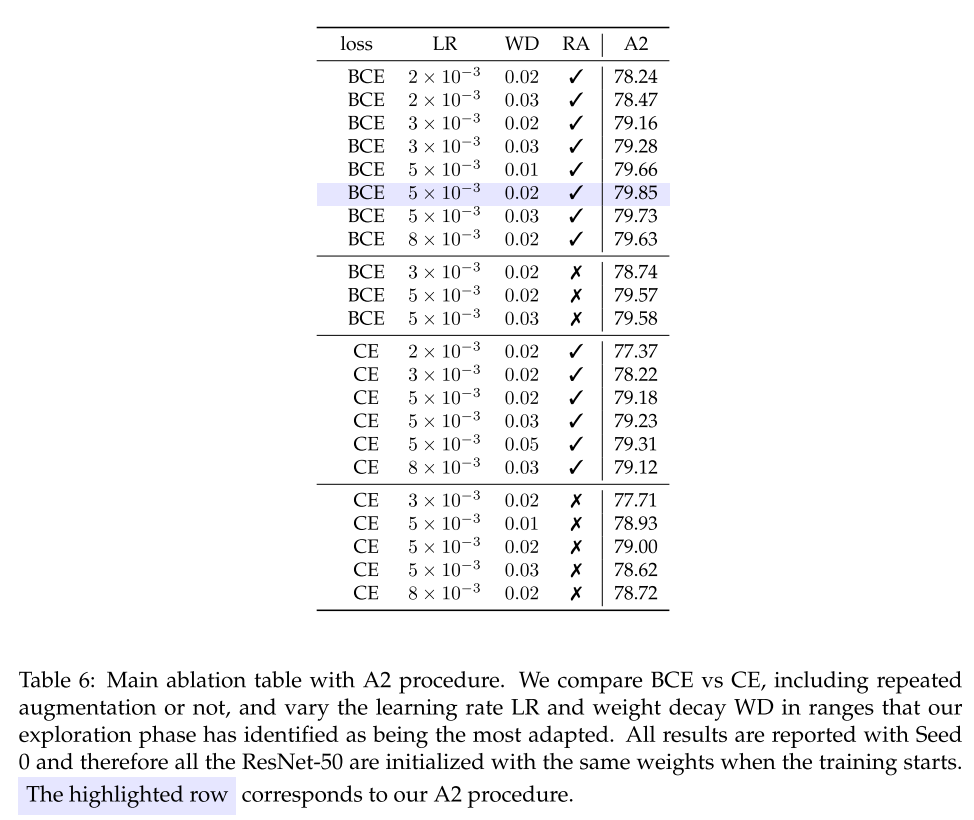
손실 함수는 BCE를 사용하는 방식에서 vanilla CE 손실을 사용하게 되면 성능이 크게 저하됩니다. 본 논문에서 말한 것과 같이 BCE의 유연성을 사용하여 Mixup/Cutmix를 합계가 1인 확률을 적용하는 선택과 반대로 multi class 1 vs all classification 문제를 활성화하는 것으로 간주합니다. 확률이 1이 되도록 하는 경우 표 8에서 보고된 것과 같이 약간 더 낮은 정확도를 얻습니다. 그래서 BCE가 CE보다 반드시 낫다는 결론은 짓지 않습니다. 하지만 이러한 손실함수를 사용함으로써 가장 높은 정확도를 달성하게 됩니다.
Repeated augmentation은 다른 하이퍼 파라미터와 복잡한 상호작용을 하게 됩니다. 학습 일정이 A3과 같이 짧거나 Mixup 매개변수의 값이 더 높은 경우에서 어떤 경우는 중립적인 결과를 보여주거나, 좋지 않은 결과를 보여준다는 것을 발견했습니다. 그래서 이는 이해가 되지 않는 부분이 있습니다. 그래서 이러한 증강은 A1 및 A2에 포함하는 것이 가장 좋았습니다.
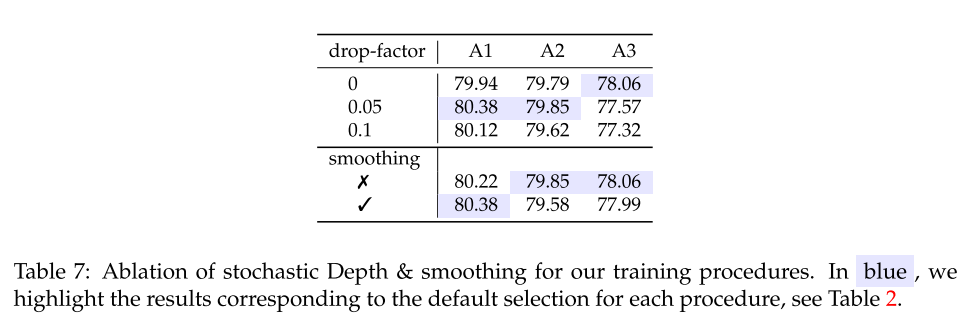
Stochastic Depth 및 Smoothing 같은 경우 A1 및 A2에 포함시켰습니다. label smoothing은 epoch 300에서 다른 하이퍼 파라미터와 다른 구성요소들이 고정된 상태에서는 효과적이지 않습니다.
Augmentation은 몇 가지 매개변수를 수정할 때 증강의 역할을 보여줍니다.

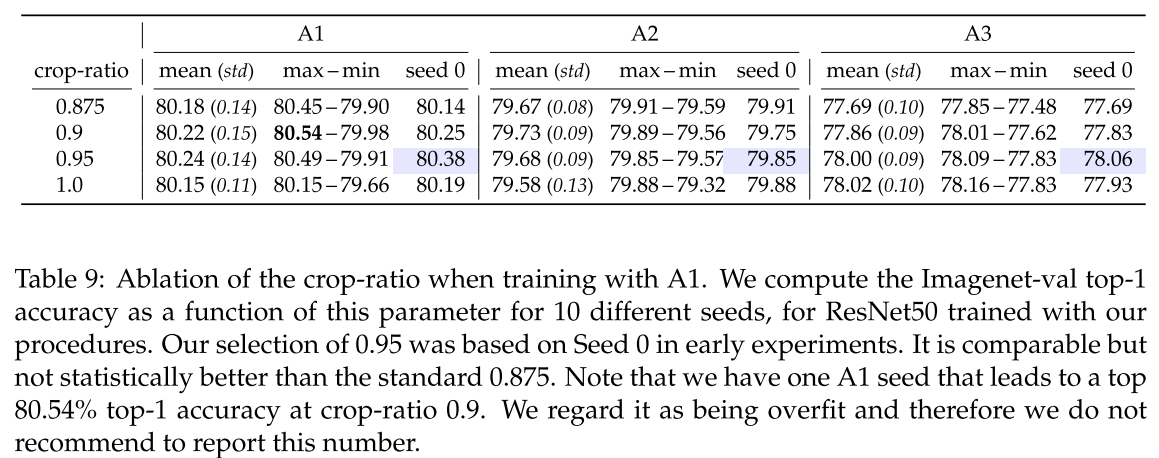
Crop-ratio는 0.875를 사용합니다. 최근 연구자들은 이 매개변수에 대해 더 큰 값을 고려하기도 합니다. 표 9를 참고하시면 좋을 듯 합니다.
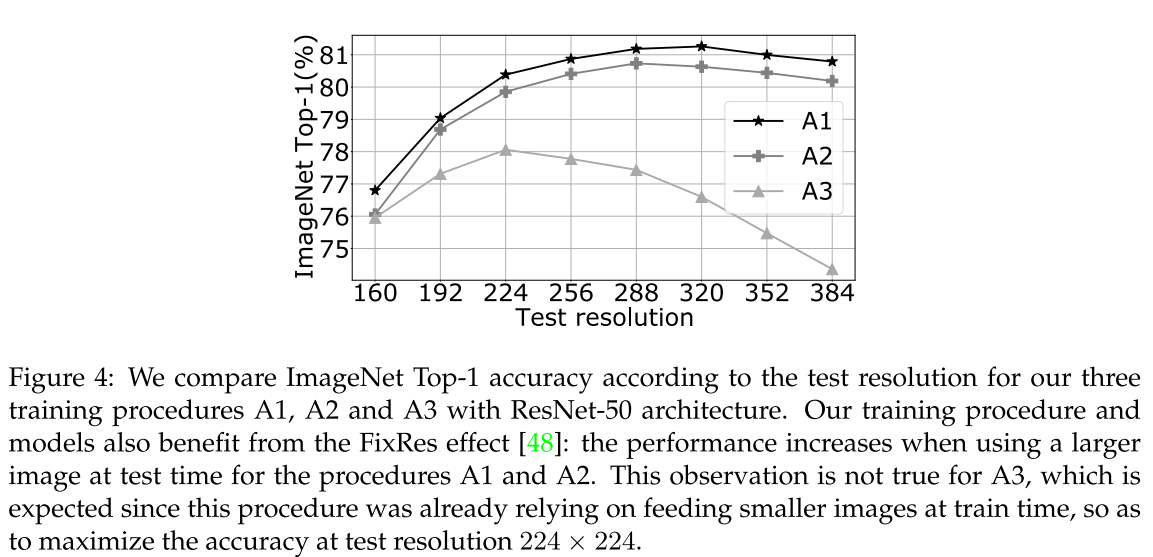
본 논문에서는 해상도 224x224에서의 성능을 주로 분석하지만, 더 큰 해상도에서도 모델을 평가합니다. 그림 4에 자세히 명시되어 있습니다. 여기서 A1과 A2로 학습된 모델이 더 높은 해상도에서 사용될 때 더 나은 성능을 가진다는 것을 보여줍니다.
Conclusion
결론입니다. 본 논문에서는 vanilla ResNet-50에 대한 새로운 학습 절차들을 제안했습니다. 새로운 구성요소들을 통합하였고, 다양한 리소스 제약 하에 다양한 학습 방법들을 탐구하기 위해 상당한 노력들을 했습니다. 그 결과 이 모델을 학습하기 위한 SOTA 기술을 확립했습니다. 하지만 이러한 방법이 보편적이라고는 하지 않는다고 하네요. 모델과 학습 하는 방법은 반드시 같이 고려되어 최적화 해야 한다고 주장하고 있습니다. 🙂